TOC
在前面《08 | 管程:并发编程的万能钥 匙》中我们提到过在并发编程领域,有 两大核心问题:一个是互斥,即同一时刻只允许一个线程 访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决 的。Java SDK 并发包通过 Lock 和 Condition 两个接口来实现管程,其中 Lock 用于解决互斥 问题,Condition 用于解决同步问题。
14|Lock和Condition(上):隐藏在并发包中的管程
再造管程的理由
原因是 synchronized 申请资源的时候,如果申请不到,线程直 接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。但我 们希望的是:
对于“不可抢占”这个条件,占用部分资源的线程进一步申请其他资源时,如果申 请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
如果我们重新设计一把互斥锁去解决这个问题,那该怎么设计呢?我觉得有三种方案。
- 能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就 进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能 够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有 机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
- 支持超时。如果线程在一段时间之内没有获取到锁,不是进入阻塞状态,而是返回一个错误, 那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
- 非阻塞地获取锁。如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有 机会释放曾经持有的锁。这样也能破坏不可抢占条件。
这三种方案可以全面弥补 synchronized 的问题。到这里相信你应该也能理解了,这三个方案就 是“重复造轮子”的主要原因,体现在 API 上,就是 Lock 接口的三个方法。详情如下:
// 支持中断的 API
void lockInterruptibly()
throws InterruptedException;
// 支持超时的 API
boolean tryLock(long time, TimeUnit unit)
throws InterruptedException;
// 支持非阻塞获取锁的 API
boolean tryLock();
如何保证可见性
Java SDK 里面锁的实现非常复杂,这里我就不展开细说了,但是原理还是 需要简单介绍一下:它是利用了 volatile 相关的 Happens-Before 规则。Java SDK 里面的 ReentrantLock,内部持有一个 volatile 的成员变量 state,获取锁的时候,会读写 state 的值; 解锁的时候,也会读写 state 的值(简化后的代码如下面所示)。也就是说,在执行 value+=1 之前,程序先读写了一次 volatile 变量 state,在执行 value+=1 之后,又读写了一次 volatile 变量 state。
根据相关的 Happens-Before 规则:
- 顺序性规则:对于线程 T1,value+=1 Happens-Before 释放锁的操作 unlock(); 2. volatile 变量规则:由于 state = 1 会先读取 state,所以线程 T1 的 unlock() 操作 Happens-Before 线程 T2 的 lock() 操作;
传递性规则:线程 T2 的 lock() 操作 Happens-Before 线程 T1 的 value+=1 。
class SampleLock { volatile int state; //加锁 lock() { // 省略代码无数 state = 1; } //解锁 unlock() { // 省略代码无数 state = 0; } }
什么是可重入锁
所谓可重入锁,顾名思义,指的是线程可以重复获取同 一把锁
用锁的最佳实践
并发大师 Doug Lea《Java 并发编程:设计原则与模式》一书中,推荐的三个用锁的最佳实践,它们分别 是:
- 永远只在更新对象的成员变量时加锁
- 永远只在访问可变的成员变量时加锁
- 永远不在调用其他对象的方法时加锁
除了并发大师 Doug Lea 推荐的三个最佳实践外,你也可以参考一些诸如:减少锁的持有时间、 减小锁的粒度等业界广为人知的规则,其实本质上它们都是相通的,不过是在该加锁的地方加锁 而已。
15|Lock和Condition(下):Dubbo如何用管程实现异步转同步?
Condition 实现了管程模型里面的条件变量。
在《08 | 管程:并发编程的万能钥匙》里我们提到过 Java 语言内置的管程里只有一个条件变 量,而 Lock&Condition 实现的管程是支持多个条件变量的,这是二者的一个重要区别。 在很多并发场景下,支持多个条件变量能够让我们的并发程序可读性更好,实现起来也更容易。 例如,实现一个阻塞队列,就需要两个条件变量。
一个阻塞队列,需要两个条件变量,一个是队列不空(空队列不允许出队),另一个是队列不满 (队列已满不允许入队),这个例子我们前面在介绍管程的时候详细说过,这里就不再赘述。相 关的代码,我这里重新列了出来,你可以温故知新一下。
public class BlockedQueue<T>{
final Lock lock = new ReentrantLock();
// 条件变量:队列不满
final Condition notFull = lock.newCondition();
// 条件变量:队列不空
final Condition notEmpty = lock.newCondition();
//入队
void enq(T x) {
lock.lock();
try {
while (队列已满){ // 等待队列不满
notFull.await();
}
// 省略入队操作...
// 入队后, 通知可出队
notEmpty.signal();
}finally {
lock.unlock();
}
}
//出队
void deq(){
lock.lock();
try {
while (队列已空){ // 等待队列不空
notEmpty.await();
}
// 省略出队操作...
// 出队后,通知可入队
notFull.signal();
}finally {
lock.unlock();
} }
}
Lock 和 Condition 实现的管程,线程等待和通知需要调用 await()、 signal()、signalAll(),它们的语义和 wait()、notify()、notifyAll() 是相同的。但是不一样的 是,Lock&Condition 实现的管程里只能使用前面的 await()、signal()、signalAll(),而后面的 wait()、notify()、notifyAll() 只有在 synchronized 实现的管程里才能使用。如果一不小心在 Lock&Condition 实现的管程里调用了 wait()、notify()、notifyAll(),那程序可就彻底玩儿完 了。
package com.meituan.hyt.test4;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class Main {
public static void main(String[] args) {
final ReentrantLock reentrantLock = new ReentrantLock();
final Condition condition = reentrantLock.newCondition();
new Thread(new Runnable() {
@Override
public void run() {
reentrantLock.lock();
System.out.println(Thread.currentThread().getName() + "拿到锁了");
System.out.println(Thread.currentThread().getName() + "等待信号");
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "拿到信号");
reentrantLock.unlock();
}
}, "线程1").start();
new Thread(new Runnable() {
@Override
public void run() {
reentrantLock.lock();
System.out.println(Thread.currentThread().getName() + "拿到锁了");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "发出信号");
condition.signalAll();
reentrantLock.unlock();
}
}, "线程2").start();
}
}
运行结果:
线程1拿到锁了
线程1等待信号
线程2拿到锁了
线程2发出信号
线程1拿到信号
原理
我们知道Lock的本质是AQS,AQS自己维护的队列是当前等待资源的队列,AQS会在资源被释放后,依次唤醒队列中从前到后的所有节点,使他们对应的线程恢复执行,直到队列为空。而Condition自己也维护了一个队列,该队列的作用是维护一个等待signal信号的队列。但是,两个队列的作用不同的,事实上,每个线程也仅仅会同时存在以上两个队列中的一个,流程是这样的:
- 线程1调用reentrantLock.lock时,尝试获取锁。如果成功,则返回,从AQS的队列中移除线程;否则阻塞,保持在AQS的等待队列中。
- 线程1调用await方法被调用时,对应操作是被加入到Condition的等待队列中,等待signal信号;同时释放锁。
- 锁被释放后,会唤醒AQS队列中的头结点,所以线程2会获取到锁。
- 线程2调用signal方法,这个时候Condition的等待队列中只有线程1一个节点,于是它被取出来,并被加入到AQS的等待队列中。注意,这个时候,线程1 并没有被唤醒,只是被加入AQS等待队列。
- signal方法执行完毕,线程2调用unLock()方法,释放锁。这个时候因为AQS中只有线程1,于是,线程1被唤醒,线程1恢复执行。 所以: 发送signal信号只是将Condition队列中的线程加到AQS的等待队列中。只有到发送signal信号的线程调用reentrantLock.unlock()释放锁后,这些线程才会被唤醒。
可以看到,整个协作过程是靠结点在AQS的等待队列和Condition的等待队列中来回移动实现的,Condition作为一个条件类,很好的自己维护了一个等待信号的队列,并在适时的时候将结点加入到AQS的等待队列中来实现的唤醒操作。
16|Semaphore:如何快速实现一个限流器?
Semaphore,现在普遍翻译为“信号量”,以前也曾被翻译成“信号灯”,因为类似现实生活里 的红绿灯,车辆能不能通行,要看是不是绿灯。同样,在编程世界里,线程能不能执行,也要看 信号量是不是允许。 信号量是由大名鼎鼎的计算机科学家迪杰斯特拉(Dijkstra)于 1965 年提出,在这之后的 15 年,信号量一直都是并发编程领域的终结者,直到 1980 年管程被提出来,我们才有了第二选 择。目前几乎所有支持并发编程的语言都支持信号量机制,所以学好信号量还是很有必要的。 下面我们首先介绍信号量模型,之后介绍如何使用信号量,最后我们再用信号量来实现一个限流器。
信号量模型
信号量模型还是很简单的,可以简单概括为:一个计数器,一个等待队列,三个方法。在信号量 模型里,计数器和等待队列对外是透明的,所以只能通过信号量模型提供的三个方法来访问它 们,这三个方法分别是:init()、down() 和 up()。你可以结合下图来形象化地理解。
这三个方法详细的语义具体如下所示。
- init():设置计数器的初始值。
- down():计数器的值减 1;如果此时计数器的值小于 0,则当前线程将被阻塞,否则当前线程 可以继续执行。
- up():计数器的值加 1;如果此时计数器的值小于或者等于 0,则唤醒等待队列中的一个线 程,并将其从等待队列中移除。
这里提到的 init()、down() 和 up() 三个方法都是原子性的,并且这个原子性是由信号量模型的 实现方保证的。在 Java SDK 里面,信号量模型是由 java.util.concurrent.Semaphore 实现的, Semaphore 这个类能够保证这三个方法都是原子操作
这里再插一句,信号量模型里面,down()、up() 这两个操作历史上最早称为 P 操作和 V 操作, 所以信号量模型也被称为 PV 原语。另外,还有些人喜欢用 semWait() 和 semSignal() 来称呼它 们,虽然叫法不同,但是语义都是相同的。在 Java SDK 并发包里,down() 和 up() 对应的则是 acquire() 和 release()。
如何使用信号量
通过上文,你应该会发现信号量的模型还是很简单的,那具体该如何使用呢?其实你想想红绿灯 就可以了。十字路口的红绿灯可以控制交通,得益于它的一个关键规则:车辆在通过路口前必须 先检查是否是绿灯,只有绿灯才能通行。这个规则和我们前面提到的锁规则是不是很类似? 其实,信号量的使用也是类似的。这里我们还是用累加器的例子来说明信号量的使用吧。在累加 器的例子里面,count+=1 操作是个临界区,只允许一个线程执行,也就是说要保证互斥。那这 种情况用信号量怎么控制呢? 其实很简单,就像我们用互斥锁一样,只需要在进入临界区之前执行一下 down() 操作,退出临 界区之前执行一下 up() 操作就可以了。
下面是 Java 代码的示例,acquire() 就是信号量里的 down() 操作,release() 就是信号量里的 up() 操作
static int count;
// 初始化信号量
static final Semaphore s = new Semaphore(1); // 用信号量保证互斥
static void addOne() {
s.acquire();
try {
count+=1;
} finally {
s.release();
}
}
下面我们再来分析一下,信号量是如何保证互斥的。假设两个线程 T1 和 T2 同时访问 addOne() 方法,当它们同时调用 acquire() 的时候,由于 acquire() 是一个原子操作,所以只能有一个线 程(假设 T1)把信号量里的计数器减为 0,另外一个线程(T2)则是将计数器减为 -1。
- 对于线 程 T1,信号量里面的计数器的值是 0,大于等于 0,所以线程 T1 会继续执行;
- 对于线程 T2,信 号量里面的计数器的值是 -1,小于 0,按照信号量模型里对 down() 操作的描述,线程 T2 将被 阻塞。所以此时只有线程 T1 会进入临界区执行count+=1;。
当线程 T1 执行 release() 操作,也就是 up() 操作的时候,信号量里计数器的值是 -1,加 1 之后 的值是 0,小于等于 0,按照信号量模型里对 up() 操作的描述,此时等待队列中的 T2 将会被唤 醒。于是 T2 在 T1 执行完临界区代码之后才获得了进入临界区执行的机会,从而保证了互斥 性。
快速实现一个限流器
上面的例子,我们用信号量实现了一个最简单的互斥锁功能。估计你会觉得奇怪,既然有 Java SDK 里面提供了 Lock,为啥还要提供一个 Semaphore ?其实实现一个互斥锁,仅仅是 Semaphore 的部分功能,Semaphore 还有一个功能是 Lock 不容易实现的,那就是: Semaphore 可以允许多个线程访问一个临界区。 现实中还有这种需求?有的。比较常见的需求就是我们工作中遇到的各种池化资源,例如连接 池、对象池、线程池等等。其中,你可能最熟悉数据库连接池,在同一时刻,一定是允许多个线 程同时使用连接池的,当然,每个连接在被释放前,是不允许其他线程使用的。 其实前不久,我在工作中也遇到了一个对象池的需求。所谓对象池呢,指的是一次性创建出 N 个 对象,之后所有的线程重复利用这 N 个对象,当然对象在被释放前,也是不允许其他线程使用 的。对象池,可以用 List 保存实例对象,这个很简单。但关键是限流器的设计,这里的限流,指 的是不允许多于 N 个线程同时进入临界区。那如何快速实现一个这样的限流器呢?这种场景,我 立刻就想到了信号量的解决方案。 信号量的计数器,在上面的例子中,我们设置成了 1,这个 1 表示只允许一个线程进入临界区, 但如果我们把计数器的值设置成对象池里对象的个数 N,就能完美解决对象池的限流问题了。下 面就是对象池的示例代码。
class ObjPool<T, R> {
final List<T> pool;
// 用信号量实现限流器
final Semaphore sem;
// 构造函数
ObjPool(int size, T t) {
pool = new Vector<T>() {};
for (int i = 0; i < size; i++) {
pool.add(t);
}
sem = new Semaphore(size);
}
// 利用对象池的对象,调用 func
R exec(Function<T, R> func) {
T t = null;
sem.acquire();
try {
t = pool.remove(0);
return func.apply(t);
finally{
pool.add(t);
sem.release();
}
}
}
// 创建对象池
ObjPool<Long, String> pool = new ObjPool<Long, String>(10, 2);
// 通过对象池获取 t,之后执行
pool.exec(t -> {
System.out.println(t);
return t.toString();
});
我们用一个 List来保存对象实例,用 Semaphore 实现限流器。关键的代码是 ObjPool 里面的 exec() 方法,这个方法里面实现了限流的功能。在这个方法里面,我们首先调用 acquire() 方法 (与之匹配的是在 finally 里面调用 release() 方法),假设对象池的大小是 10,信号量的计数 器初始化为 10,那么前 10 个线程调用 acquire() 方法,都能继续执行,相当于通过了信号灯, 而其他线程则会阻塞在 acquire() 方法上。对于通过信号灯的线程,我们为每个线程分配了一个 对象 t(这个分配工作是通过 pool.remove(0) 实现的),分配完之后会执行一个回调函数 func,而函数的参数正是前面分配的对象 t ;执行完回调函数之后,它们就会释放对象(这个释 放工作是通过 pool.add(t) 实现的),同时调用 release() 方法来更新信号量的计数器。如果此 时信号量里计数器的值小于等于 0,那么说明有线程在等待,此时会自动唤醒等待的线程。
简言之,使用信号量,我们可以轻松地实现一个限流器,使用起来还是非常简单的
总结
信号量在 Java 语言里面名气并不算大,但是在其他语言里却是很有知名度的。Java 在并发编程 领域走的很快,重点支持的还是管程模型。 管程模型理论上解决了信号量模型的一些不足,主要 体现在易用性和工程化方面,例如用信号量解决我们曾经提到过的阻塞队列问题,就比管程模型 麻烦很多,你如果感兴趣,可以课下了解和尝试一下。
17|ReadWriteLock:如何快速实现一个完备的缓存?
前面我们介绍了管程和信号量这两个同步原语在 Java 语言中的实现,理论上用这两个同步原语中 任何一个都可以解决所有的并发问题。那 Java SDK 并发包里为什么还有很多其他的工具类呢?原 因很简单:分场景优化性能,提升易用性。
读写锁与互斥锁的一个重要区别就是读写锁允许多个线程同时读共享变量,而互斥锁是不允许 的,这是读写锁在读多写少场景下性能优于互斥锁的关键。但读写锁的写操作是互斥的,当一个 线程在写共享变量的时候,是不允许其他线程执行写操作和读操作。
快速实现一个缓存
class Cache<K,V> {
final Map<k, V> m = new HashMap();
final ReadWriteLock wrl = new ReentrantReadWriteLock();
//读锁
final Lock r = rwl.readLock();
//写锁
final Lock w = rwl.writeLock();
//读缓存
V get(K key){
r.lock();
try{
return m.get(key);
}finally{
r.unlock();
}
}
//写缓存
V put(String key,Data v){
w.lock();
try {
return m.put(key,v);
}finally{
w.unlock();
}
}
}
18|StampedLock:有没有比读写锁更快的锁?
“读写锁允许多个线程同时读 共享变量,适用于读多写少的场景”。那在读多写少的场景中,还有没有更快的技术方案呢?还 真有,Java 在 1.8 这个版本里,提供了一种叫 StampedLock 的锁,它的性能就比读写锁还要好。
我们知道在ReadWriteLock中写和读是互斥的,也就是如果有一个线程在写共享变量的话,其他线程读共享变量都会阻塞。
StampedLock把读分为了悲观读和乐观读,悲观读就等价于ReadWriteLock的读,而乐观读在一个线程写共享变量时,不会被阻塞,乐观读是不加锁的(可以理解为带version的读)。所以没锁肯定是比有锁的性能好,这样的话在大并发读情况下效率就更高了!
StampedLock 支持的三种锁模式
ReadWriteLock 支持两种模式:一种是读锁,一种是写锁。
而 StampedLock 支持三种模式,分别 是:写锁、悲观读锁和乐观读。
其中,写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的 语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读 锁是互斥的。不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个 stamp;然后解锁的时候,需要传入这个 stamp。相关代码如下:
final StampedLock sl = new StampedLock();
//获取 /释放悲观读锁示意代码
long stamp = sl.readLock();
try{
//省略业务相关代码
} finally{
sl.unlockRead(stamp);
}
//获取 /释放写锁示意代码
long stamp = sl.writeLock();
try{
//省略业务相关代码
} finally{
sl.unlockWrite(stamp);
}
StampedLock 的性能之所以比 ReadWriteLock 还要好,其关键是 StampedLock 支持乐观读的方 式。ReadWriteLock 支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻 塞;而 StampedLock 提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作 都被阻塞
我们用的是“乐观读”这个词,而不是“乐观读锁”,是要提醒你,乐观读这个操作 是无锁的,所以相比较 ReadWriteLock 的读锁,乐观读的性能更好一些。
文中下面这段代码是出自 Java SDK 官方示例,并略做了修改。在 distanceFromOrigin() 这个方法 中,首先通过调用 tryOptimisticRead() 获取了一个 stamp,这里的 tryOptimisticRead() 就是我们 前面提到的乐观读。之后将共享变量 x 和 y 读入方法的局部变量中,不过需要注意的是,由于 tryOptimisticRead() 是无锁的,所以共享变量 x 和 y 读入方法局部变量时,x 和 y 有可能被其他 线程修改了。因此最后读完之后,还需要再次验证一下是否存在写操作,这个验证操作是通过调 用 validate(stamp) 来实现的。
class Point {
private int x, y;
final StampedLock sl = new StampedLock();
//计算到原点的距离
int distanceFromOrigin() {
//乐观读
long stamp = sl.tryOptimisticRead();
//读入局部变量,读的过程数据可能被修改
int curX = x, curY = y;
//判断执行读操作期间,是否存在写操作,如果存在 sl.validate 返回 false
if (!sl.validate(stamp)){
//升级为悲观读锁
stamp = sl.readLock();
try {
curX = x;
curY = y;
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(
curX * curX + curY * curY);
} }
在上面这个代码示例中,如果执行乐观读操作的期间,存在写操作,会把乐观读升级为悲观读锁。这个做法挺合理的,否则你就需要在一个循环里反复执行乐观读,直到执行乐观读操作的期 间没有写操作(只有这样才能保证 x 和 y 的正确性和一致性),而循环读会浪费大量的 CPU。升 级为悲观读锁,代码简练且不易出错,建议你在具体实践时也采用这样的方法。
StampedLock 使用注意事项
StampedLock 的功能仅仅是 ReadWriteLock 的子集
- StampedLock 不支持重入
- 另外,StampedLock 的悲观读锁、写锁都不支持条件变量
如果线程阻塞在 StampedLock 的 readLock() 或者 writeLock() 上时,此时调用该阻塞线程的 interrupt() 方法,会导致 CPU 飙升。所以,使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的 悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly()
public long readLock() { long s = state, next; // bypass acquireRead on common uncontended case return ((whead == wtail && (s & ABITS) < RFULL && U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ? next : acquireRead(false, 0L)); //当CAS失败之后就会尝试申请锁,注意第一个参数是false } public long writeLock() { long s, next; // bypass acquireWrite in fully unlocked case only return ((((s = state) & ABITS) == 0L && U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ? next : acquireWrite(false, 0L)); //当CAS失败之后就会尝试申请锁,注意第一个参数是false } //就拿acquireWrite举例,acquireRead也是类似的。 private long acquireWrite(boolean interruptible, long deadline) { WNode node = null, p; for (int spins = -1;;) { // spin while enqueuing //省略代码无数 if (interruptible && Thread.interrupted()) return cancelWaiter(node, node, true); } }
首先里面是个无限循环,然后 if (interruptible && Thread.interrupted())已经得知调用的interruptible参数传入的是false,所以Thread.interrupted()也不会执行到,也一定调用不到cancelWaiter,所以就一直循环循环,CPU使用率就会涨涨涨。
所以如果要使用中断功能就得用readLockInterruptibly()或者writeLockInterruptibly()来获得锁。
19|CountDownLatch和CyclicBarrier:如何让多线程步调一致?
版本一
while(存在未对账订单){
// 查询未对账订单
pos = getPOrders();
// 查询派送单
dos = getDOrders();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
利用并行优化对账系统
join() 的作用 让父线程等待子线程结束之后才能继续运行。
我们来看看在 Java 7 Concurrency Cookbook 中相关的描述(很清楚地说明了 join() 的作用):
Waiting for the finalization of a thread
In some situations, we will have to wait for the finalization of a thread. For example, we may have a program that will begin initializing the resources it needs before proceeding with the rest of the execution. We can run the initialization tasks as threads and wait for its finalization before continuing with the rest of the program. For this purpose, we can use the join() method of the Thread class.When we call this method using a thread object, it suspends the execution of the calling thread until the object called finishes its execution.
当我们调用某个线程的这个方法时,这个方法会挂起调用线程,直到被调用线程结束执行,调用线程才会继续执行。
版本二
while(存在未对账订单){
// 查询未对账订单
Thread T1 = new Thread(()->{
pos = getPOrders();
});
T1.start();
// 查询派送单
Thread T2 = new Thread(()->{
dos = getDOrders();
});
T2.start();
// 等待 T1、T2 结束
T1.join();
T2.join();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
用 CountDownLatch 实现线程等待
经过上面的优化之后,基本上可以跟老板汇报收工了,但还是有点美中不足,相信你也发现了, while 循环里面每次都会创建新的线程,而创建线程可是个耗时的操作。所以最好是创建出来的 线程能够循环利用,估计这时你已经想到线程池了,是的,线程池就能解决这个问题。
而下面的代码就是用线程池优化后的:我们首先创建了一个固定大小为 2 的线程池,之后在 while 循环里重复利用。一切看上去都很顺利,但是有个问题好像无解了,那就是主线程如何知 道 getPOrders() 和 getDOrders() 这两个操作什么时候执行完。前面主线程通过调用线程 T1 和 T2的 join() 方法来等待线程 T1 和 T2 退出,但是在线程池的方案里,线程根本就不会退出,所以 join() 方法已经失效了。
// 创建 2 个线程的线程池 Executor executor =
Executors.newFixedThreadPool(2); while(存在未对账订单){
// 计数器初始化为 2 CountDownLatch latch =
new CountDownLatch(2);
// 查询未对账订单
executor.execute(()-> {
pos = getPOrders();
latch.countDown();
});
// 查询派送单
executor.execute(()-> {
dos = getDOrders();
latch.countDown();
});
// 等待两个查询操作结束
latch.await();
// 执行对账操作
diff = check(pos, dos);
// 差异写入差异库
save(diff);
}
进一步优化性能
下面再来看如何用双队列来实现完全的并行。一个最直接的想法是:一个线程 T1 执行订单的查 询工作,一个线程 T2 执行派送单的查询工作,当线程 T1 和 T2 都各自生产完 1 条数据的时候, 通知线程 T3 执行对账操作。这个想法虽看上去简单,但其实还隐藏着一个条件,那就是线程 T1 和线程 T2 的工作要步调一致,不能一个跑得太快,一个跑得太慢,只有这样才能做到各自生产 完 1 条数据的时候,通知线程 T3。
用 CyclicBarrier 实现线程同步
下面我们就来实现上面提到的方案。这个方案的难点有两个:一个是线程 T1 和 T2 要做到步调一 致,另一个是要能够通知到线程 T3。
你依然可以利用一个计数器来解决这两个难点,计数器初始化为 2,线程 T1 和 T2 生产完一条数 据都将计数器减 1,如果计数器大于 0 则线程 T1 或者 T2 等待。如果计数器等于 0,则通知线程 T3,并唤醒等待的线程 T1 或者 T2,与此同时,将计数器重置为 2,这样线程 T1 和线程 T2 生产 下一条数据的时候就可以继续使用这个计数器了。
同样,还是建议你不要在实际项目中这么做,因为 Java 并发包里也已经提供了相关的工具 类:CyclicBarrier。在下面的代码中,我们首先创建了一个计数器初始值为 2 的 CyclicBarrier, 你需要注意的是创建 CyclicBarrier 的时候,我们还传入了一个回调函数,当计数器减到 0 的时候,会调用这个回调函数。
线程 T1 负责查询订单,当查出一条时,调用 barrier.await()
来将计数器减 1,同时等待计数器变成 0;线程 T2 负责查询派送单,当查出一条时,也调用 barrier.await() 来将计数器减1,同时等待计数器变成0;当T1和T2都调用 barrier.await() 的时候,计数器会减到0,此时T1和T2就可以执行下一条语句了,同时 会调用 barrier 的回调函数来执行对账操作。
非常值得一提的是,CyclicBarrier 的计数器有自动重置的功能,当减到 0 的时候,会自动重置你 设置的初始值。这个功能用起来实在是太方便了。
// 订单队列
Vector<P> pos;
// 派送单队列
Vector<D> dos;
// 执行回调的线程池
Executor executor = Executors.newFixedThreadPool(1);
final CyclicBarrier barrier =
new CyclicBarrier(2, ()->{
executor.execute(()->check());
});
void check(){
P p = pos.remove(0);
D d = dos.remove(0);
// 执行对账操作
diff = check(p, d);
// 差异写入差异库
save(diff);
}
void checkAll(){
// 循环查询订单库
Thread T1 = new Thread(()->{
while(存在未对账订单){
// 查询订单库
pos.add(getPOrders());
// 等待
barrier.await();
}
}
T1.start();
// 循环查询运单库
Thread T2 = new Thread(()->{
while(存在未对账订单){
// 查询运单库
dos.add(getDOrders());
// 等待
barrier.await();
}
}
T2.start();
}
20|并发容器:都有哪些“坑”需要我们填?
同步容器及其注意事项
在前面《12 | 如何用面向对象思想写好并发程序?》我们讲过实现思路其实很简单,只要把非线 程安全的容器封装在对象内部,然后控制好访问路径就可以了。 下面我们就以 ArrayList 为例,看看如何将它变成线程安全的。在下面的代码中,SafeArrayList 内部持有一个 ArrayList 的实例 c,所有访问 c 的方法我们都增加了 synchronized 关键字,需要 注意的是我们还增加了一个 addIfNotExist() 方法,这个方法也是用 synchronized 来保证原子性 的。
SafeArrayList<T>{
// 封装 ArrayList
List<T> c = new ArrayList<>();
// 控制访问路径
synchronized
T get(int idx){
return c.get(idx);
}
synchronized
void add(int idx, T t) {
c.add(idx, t);
}
synchronized
boolean addIfNotExist(T t){
if(!c.contains(t)) {
c.add(t);
return true;
}
return false;
}
}
看到这里,你可能会举一反三,然后想到:所有非线程安全的类是不是都可以用这种包装的方式 来实现线程安全呢?其实这一点不止你想到了,Java SDK 的开发人员也想到了,所以他们在 Collections 这个类中还提供了一套完备的包装类,比如下面的示例代码中,分别把 ArrayList、 HashSet 和 HashMap 包装成了线程安全的 List、Set 和 Map
List list = Collections. synchronizedList(new ArrayList());
Set set = Collections. synchronizedSet(new HashSet());
Map map = Collections. synchronizedMap(new HashMap());
组合操作需要注意竞态条件问题,例如上面提到的 addIfNotExist() 方法就包 含组合操作。组合操作往往隐藏着竞态条件问题,即便每个操作都能保证原子性,也并不能保证 组合操作的原子性,这个一定要注意 在容器领域一个容易被忽视的“坑”是用迭代器遍历容器,例如在下面的代码中,通过迭代器遍 历容器 list,对每个元素调用 foo() 方法,这就存在并发问题,这些组合的操作不具备原子性。
List list = Collections. synchronizedList(new ArrayList());
Iterator i = list.iterator();
while (i.hasNext())
foo(i.next());
而正确做法是下面这样,锁住 list 之后再执行遍历操作。如果你查看 Collections 内部的包装类源 码,你会发现包装类的公共方法锁的是对象的 this,其实就是我们这里的 list,所以锁住 list 绝对 是线程安全的
synchronizedList(new ArrayList());
synchronized (list) {
Iterator i = list.iterator();
while (i.hasNext())
foo(i.next());
}
上面我们提到的这些经过包装后线程安全容器,都是基于 synchronized 这个同步关键字实现的, 所以也被称为同步容器。Java 提供的同步容器还有 Vector、Stack 和 Hashtable,这三个容器不 是基于包装类实现的,但同样是基于 synchronized 实现的,对这三个容器的遍历,同样要加锁保 证互斥。
并发容器及其注意事项
Java 在 1.5 版本之前所谓的线程安全的容器,主要指的就是同步容器。不过同步容器有个最大的 问题,那就是性能差,所有方法都用 synchronized 来保证互斥,串行度太高了。因此 Java 在 1.5 及之后版本提供了性能更高的容器,我们一般称为并发容器。
并发容器虽然数量非常多,但依然是前面我们提到的四大类:List、Map、Set 和 Queue,下面的 并发容器关系图,基本上把我们经常用的容器都覆盖到了。
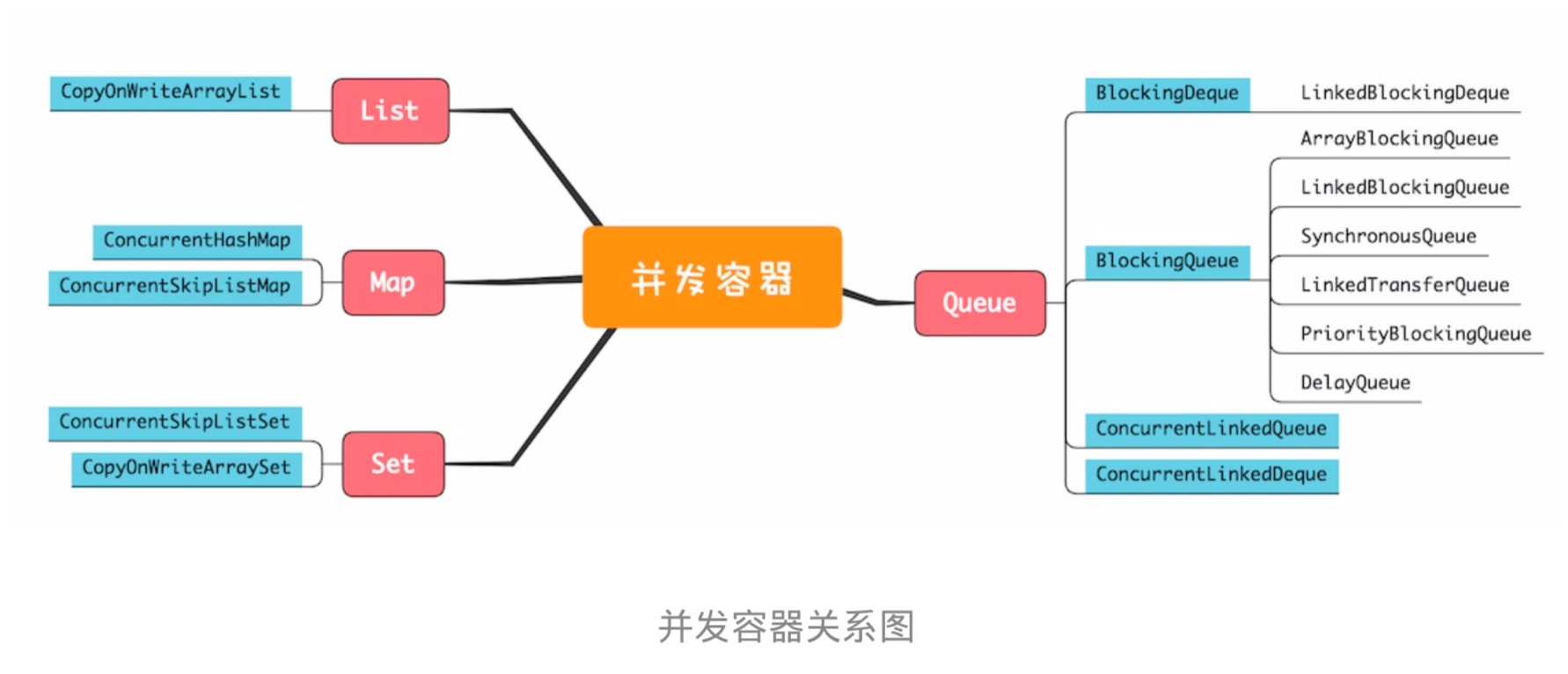
####(一)List List 里面只有一个实现类就是CopyOnWriteArrayList。CopyOnWrite,顾名思义就是写的时候会 将共享变量新复制一份出来,这样做的好处是读操作完全无锁。
(二)Map
Map 接口的两个实现是 ConcurrentHashMap 和 ConcurrentSkipListMap,它们从应用的角度来 看,主要区别在于ConcurrentHashMap 的 key 是无序的,而 ConcurrentSkipListMap 的 key 是 有序的。所以如果你需要保证 key 的顺序,就只能使用 ConcurrentSkipListMap。
(三)Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面 讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap,它们的原理都是一样的,这里就不再 赘述了。
(四)Queue
Java 并发包里面 Queue 这类并发容器是最复杂的,你可以从以下两个维度来分类。一个维度是 阻塞与非阻塞,所谓阻塞指的是当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。 另一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入 队出队。Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队 列使用 Deque 标识
- 单端阻塞队列:其实现有 ArrayBlockingQueue、LinkedBlockingQueue、 SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue。
- 双端阻塞队列: 其实现是 LinkedBlockingDeque。
- 单端非阻塞队列:其实现是 ConcurrentLinkedQueue。
- 双端非阻塞队列:其实现是 ConcurrentLinkedDeque。
总结
Java 并发容器的内容很多,但鉴于篇幅有限,我们只是对一些关键点进行了梳理和介绍。 而在实际工作中,你不单要清楚每种容器的特性,还要能选对容器,这才是关键,至于每种容器 的用法,用的时候看一下 API 说明就可以了,这些容器的使用都不难。在文中,我们甚至都没有 介绍 Java 容器的快速失败机制(Fail-Fast),原因就在于当你选对容器的时候,根本不会触发 它。