TOC
前面我们多次提到一个累加器的例子,示例代码如下。在这个例子中,add10K() 这个方法不是线程安全的,问题就出在变量 count 的可见性和 count+=1 的原子性上。可见性问题可以用 volatile 来解决,而原子性问题我们前面一直都是采用的互斥锁方案。
21|原子类:无锁工具类的典范(重点学习)
public class Test{
long count = 0;
void add10k(){
int idx = 0;
while(idx++<1000) {
count +=1;
}
}
}
其实对于简单的原子性问题,还有一种无锁方案。Java SDK 并发包将这种无锁方案封装提炼之 后,实现了一系列的原子类。不过,在深入介绍原子类的实现之前,我们先看看如何利用原子类 解决累加器问题,这样你会对原子类有个初步的认识。
在下面的代码中,我们将原来的 long 型变量 count 替换为了原子类 AtomicLong,原来的count +=1
替换成了count.getAndIncrement(),仅需要这两处简单的改动就能使 add10K()方法变成线程安 全的,原子类的使用还是挺简单的。
public class Test{
AtomicLong count = new AtomicLong(0);
void add10k(){
int idx = 0;
while(idx++<1000) {
count.getAndIncrement();
}
}
}
无锁方案相对互斥锁方案,最大的好处就是性能。互斥锁方案为了保证互斥性,需要执行加锁、 解锁操作,而加锁、解锁操作本身就消耗性能;同时拿不到锁的线程还会进入阻塞状态,进而触 发线程切换,线程切换对性能的消耗也很大。 相比之下,无锁方案则完全没有加锁、解锁的性能 消耗,同时还能保证互斥性,既解决了问题,又没有带来新的问题,可谓绝佳方案。那它是如何 做到的呢?
无锁方案的实现原理
其实原子类性能高的秘密很简单,硬件支持而已。CPU 为了解决并发问题,提供了 CAS 指令 (CAS,全称是 Compare And Swap,即“比较并交换”)。
CAS 指令包含 3 个参数:共享变量 的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
你可以通过下面 CAS 指令的模拟代码来理解 CAS 的工作原理。在下面的模拟程序中有两个参数, 一个是期望值 expect,另一个是需要写入的新值 newValue,只有当目前 count 的值和期望值 expect 相等时,才会将 count 更新为 newValue。
class SimulatedCAS{
int count;
synchronized int cas(
int expect, int newValue){
// 读目前 count 的值
int curValue = count;
// 比较目前 count 值是否 == 期望值
if(curValue == expect){
// 如果是,则更新 count 的值
count = newValue;
}
// 返回写入前的值
return curValue;
}
}
你仔细地再次思考一下这句话,“只有当目前 count 的值和期望值 expect 相等时,才会将 count 更新为 newValue。”要怎么理解这句话呢?
对于前面提到的累加器的例子,count += 1
的一个核心问题是:基于内存中 count 的当前值 A 计算出来的count+=1为 A+1,在将 A+1 写入
内存的时候,很可能此时内存中 count 已经被其他线程更新过了,这样就会导致错误地覆盖其他 线程写入的值(如果你觉得理解起来还有困难,建议你再重新看看《01 | 可见性、原子性和有序 性问题:并发编程 Bug 的源头》)。也就是说,只有当内存中 count 的值等于期望值 A 时,才能 将内存中 count 的值更新为计算结果 A+1,这不就是 CAS 的语义吗
使用 CAS 来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。例如,实现 一个线程安全的count += 1
操作,“CAS+ 自旋”的实现方案如下所示,首先计算 newValue = count+1,如果 cas(count,newValue) 返回的值不等于 count,则意味着线程在执行完代码1处之后,执行代码2 处之前,count 的值被其他线程更新过。那此时该怎么处理呢?可以采用自旋方案,就像下面代 码中展示的,可以重新读 count 最新的值来计算 newValue 并尝试再次更新,直到成功。
class SimulatedCAS{ volatile int count; // 实现 count+=1
addOne(){
do{
newValue = count+1; //1
}while(count != cas(count,newValue)//2
}
// 模拟实现 CAS,仅用来帮助理解
synchronized int cas(
int expect, int newValue){
// 读目前 count 的值
int curValue = count;
// 比较目前 count 值是否 == 期望值
if(curValue == expect){
// 如果是,则更新 count 的值
count= newValue;
}
// 返回写入前的值
return curValue;
}
}
通过上面的示例代码,想必你已经发现了,CAS 这种无锁方案,完全没有加锁、解锁操作,即便 两个线程完全同时执行 addOne() 方法,也不会有线程被阻塞,所以相对于互斥锁方案来说,性 能好了很多。 但是在 CAS 方案中,有一个问题可能会常被你忽略,那就是ABA的问题。什么是 ABA 问题呢?
前面我们提到“如果 cas(count,newValue) 返回的值不等于count,意味着线程在执行完代码1处 之后,执行代码2处之前,count 的值被其他线程更新过”,那如果 cas(count,newValue) 返回 的值等于count,是否就能够认为 count 的值没有被其他线程更新过呢?显然不是的,假设 count 原本是 A,线程 T1 在执行完代码1处之后,执行代码2处之前,有可能 count 被线程 T2 更新成 了 B,之后又被 T3 更新回了 A,这样线程 T1 虽然看到的一直是 A,但是其实已经被其他线程 更新过了,这就是 ABA 问题。
可能大多数情况下我们并不关心 ABA 问题,例如数值的原子递增,但也不能所有情况下都不关 心,例如 原子化的更新对象很可能就需要关心 ABA 问题,因为两个 A 虽然相等,但是第二个 A 的属性可能已经发生变化了。所以在使用 CAS 方案的时候,一定要先 check 一下。
看 Java 如何实现原子化的 count += 1
在本文开始部分,我们使用原子类AtomicLong的getAndIncrement()方法替代了count += 1 ,从而实现了线程安全。原子类 AtomicLong 的getAndIncrement()方法内部就是基于 CAS 实现
的,下面我们来看看Java是如何使用CAS来实现原子化的count += 1的。
在 Java 1.8 版本中,getAndIncrement() 方法会转调 unsafe.getAndAddLong()方法。这里 this 和valueOffset两个参数可以唯一确定共享变量的内存地址。
final long getAndIncrement() {
return unsafe.getAndAddLong( this, valueOffset, 1L);
}
unsafe.getAndAddLong() 方法的源码如下,该方法首先会在内存中读取共享变量的值,之后循环 调用 compareAndSwapLong() 方法来尝试设置共享变量的值,直到成功为止。 compareAndSwapLong()是一个 native 方法,只有当内存中共享变量的值等于 expected 时,才 会将共享变量的值更新为 x,并且返回 true;否则返回 fasle。compareAndSwapLong 的语义和 CAS 指令的语义的差别仅仅是返回值不同而已。
public final long getAndAddLong( Object o, long offset, long delta){ long v;
do{
// 读取内存中的值
v = getLongVolatile(o, offset);
} while (!compareAndSwapLong(
o, offset, v, v + delta));
return v;
}
// 原子性地将变量更新为 x
// 条件是内存中的值等于 expected
// 更新成功则返回 true
native boolean compareAndSwapLong( Object o, long offset, long expected, long x);
另外,需要你注意的是,getAndAddLong()方法的实现,基本上就是 CAS 使用的经典范例。所以 请你再次体会下面这段抽象后的代码片段,它在很多无锁程序中经常出现。Java 提供的原子类里 面 CAS 一般被实现为 compareAndSet(),compareAndSet() 的语义和 CAS 指令的语义的差别仅 仅是返回值不同而已,compareAndSet() 里面如果更新成功,则会返回 true,否则返回 false。
do {
// 获取当前值
oldV = xxxx;
// 根据当前值计算新值 newV = ...oldV...
}while(!compareAndSet(oldV,newV);
原子类概览
Java SDK 并发包里提供的原子类内容很丰富,我们可以将它们分为五个类别:原子化的基本数据 类型、原子化的对象引用类型、原子化数组、原子化对象属性更新器和原子化的累加器。这五个 类别提供的方法基本上是相似的,并且每个类别都有若干原子类,你可以通过下面的原子类组成 概览图来获得一个全局的印象。下面我们详细解读这五个类别。
1. 原子化的基本数据类型
相关实现有 AtomicBoolean、AtomicInteger 和 AtomicLong,提供的方法主要有以下这些,详情 你可以参考 SDK 的源代码,都很简单,这里就不详细介绍了。
2. 原子化的对象引用类型
相关实现有 AtomicReference、AtomicStampedReference 和 AtomicMarkableReference,利用 它们可以实现对象引用的原子化更新.不过需要注意的是,对象引用的更新需要重点关注 ABA 问题, AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题
解决 ABA 问题的思路其实很简单,增加一个版本号维度就可以了,这个和我们在《18 | StampedLock:有没有比读写锁更快的锁?》介绍的乐观锁机制很类似,每次执行 CAS 操作,附加再更新一个版本号,只要保证版本号是递增的,那么即便 A 变成 B 之后再变回 A,版本号也不 会变回来(版本号递增的)
- AtomicStampedReference 实现的 CAS 方法就增加了版本号参数
- AtomicMarkableReference 的实现机制则更简单,将版本号简化成了一个 Boolean
3. 原子化数组
相关实现有 AtomicIntegerArray、AtomicLongArray 和 AtomicReferenceArray,利用这些原子 类,我们可以原子化地更新数组里面的每一个元素。
4. 原子化对象属性更新器
相关实现有 AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater,利用它们可以原子化地更新对象的属性,这三个方法都是利用反 射机制实现的,创建更新器的方法如下:
public static <U>
AtomicXXXFieldUpdater<U>
newUpdater(Class<U> tclass,
String fieldName)
5. 原子化的累加器
DoubleAccumulator、DoubleAdder、LongAccumulator 和 LongAdder,这四个类仅仅用来执行 累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。如果你 仅仅需要累加操作,使用原子化的累加器性能会更好。
总结
无锁方案相对于互斥锁方案,优点非常多,首先性能好,其次是基本不会出现死锁问题(但可能 出现饥饿和活锁问题,因为自旋会反复重试)。Java 提供的原子类大部分都实现了compareAndSet()方法,基于 compareAndSet()方法,你可以构建自己的无锁数据结构,但是建 议你不要这样做,这个工作最好还是让大师们去完成,原因是无锁算法没你想象的那么简单。
Java 提供的原子类能够解决一些简单的原子性问题,但你可能会发现,上面我们所有原子类的方法都是针对一个共享变量的,如果你需要解决多个变量的原子性问题,建议还是使用互斥锁方案。原子类虽好,但使用要慎之又慎。
22|Executor与线程池:如何创建正确的线程池?
虽然在Java语言中创建线程看上去就像创建一个对象一样简单,只需要new Thread()就可以了,但实际上创 建线程远不是创建一个对象那么简单。创建对象,仅仅是在JVM的堆里分配一块内存而已;而创建一个线 程,却需要调用操作系统内核的API,然后操作系统要为线程分配一系列的资源,这个成本就很高了,所以 线程是一个重量级的对象,应该避免频繁创建和销毁。
线程池的需求是如此普遍,所以Java SDK并发包自然也少不了它。但是很多人在初次接触并发包里线程池相 关的工具类时,多少会都有点蒙,不知道该从哪里入手,我觉得根本原因在于线程池和一般意义上的池化资 源是不同的。一般意义上的池化资源,都是下面这样,当你需要资源的时候就调用acquire()方法来申请资 源,用完之后就调用release()释放资源。若你带着这个固有模型来看并发包里线程池相关的工具类时,会很 遗憾地发现它们完全匹配不上,Java提供的线程池里面压根就没有申请线程和释放线程的方法。
class XXXPool{
// 获取池化资源 XXX acquire() { }
// 释放池化资源
void release(XXX x){ }
}
### 线程池是一种生产者-消费者模式
为什么线程池没有采用一般意义上池化资源的设计方法呢?如果线程池采用一般意义上池化资源的设计方 法,应该是下面示例代码这样。你可以来思考一下,假设我们获取到一个空闲线程T1,然后该如何使用T1 呢?你期望的可能是这样:通过调用T1的execute()方法,传入一个Runnable对象来执行具体业务逻辑,就 像通过构造函数Thread(Runnable target)创建线程一样。可惜的是,你翻遍Thread对象的所有方法,都不 存在类似execute(Runnable target)这样的公共方法。
线程池的使用方是生产者,线程池本身是消费者。 在下面的示例代码中,我们创建了一个非常简单的线程池MyThreadPool,你可以通过它来理解线程池的工 作原理。
//简化的线程池,仅用来说明工作原理 class MyThreadPool{
//利用阻塞队列实现生产者-消费者模式 BlockingQueue<Runnable> workQueue; //保存内部工作线程
List<WorkerThread> threads = new ArrayList<>();
// 构造方法 MyThreadPool(int poolSize,
BlockingQueue<Runnable> workQueue){ this.workQueue = workQueue;
// 创建工作线程
for(int idx=0; idx<poolSize; idx++){
WorkerThread work = new WorkerThread();
work.start();
threads.add(work);
} }
// 提交任务
void execute(Runnable command){
workQueue.put(command);
}
// 工作线程负责消费任务,并执行任务 class WorkerThread extends Thread{
public void run() { //循环取任务并执行 while(true){ 1
Runnable task = workQueue.take();
task.run();
}
} }
}
/** 下面是使用示例 **/
// 创建有界阻塞队列 BlockingQueue<Runnable> workQueue =
new LinkedBlockingQueue<>(2);
// 创建线程池
MyThreadPool pool = new MyThreadPool(
10, workQueue); // 提交任务 pool.execute(()->{
System.out.println("hello");
});
在MyThreadPool的内部,我们维护了一个阻塞队列workQueue和一组工作线程,工作线程的个数由构造函 数中的poolSize来指定。用户通过调用execute()方法来提交Runnable任务,execute()方法的内部实现仅仅 是将任务加入到workQueue中。MyThreadPool内部维护的工作线程会消费workQueue中的任务并执行任 务,相关的代码就是代码1处的while循环。线程池主要的工作原理就这些,是不是还挺简单的?
Java并发包里提供的线程池,远比我们上面的示例代码强大得多,当然也复杂得多。Java提供的线程池相关 的工具类中,最核心的是ThreadPoolExecutor,通过名字你也能看出来,它强调的是Executor,而不是一般 意义上的池化资源。
ThreadPoolExecutor的构造函数非常复杂,如下面代码所示,这个最完备的构造函数有7个参数。
ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
下面我们一一介绍这些参数的意义,你可以把线程池类比为一个项目组,而线程就是项目组的成员。
- corePoolSize:表示线程池保有的最小线程数。有些项目很闲,但是也不能把人都撤了,至少要留corePoolSize个人坚守阵地。
- maximumPoolSize:表示线程池创建的最大线程数。当项目很忙时,就需要加人,但是也不能无限制地 加,最多就加到maximumPoolSize个人。当项目闲下来时,就要撤人了,最多能撤到corePoolSize个人。
- keepAliveTime & unit:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?很简 单,一个线程如果在一段时间内,都没有执行任务,说明很闲,keepAliveTime 和 unit 就是用来定义这 个“一段时间”的参数。也就是说,如果一个线程空闲了keepAliveTime & unit这么久,而且线程池 的线程数大于 corePoolSize ,那么这个空闲的线程就要被回收了。
- workQueue:工作队列,和上面示例代码的工作队列同义。
- threadFactory:通过这个参数你可以自定义如何创建线程,例如你可以给线程指定一个有意义的名字。
- handler:通过这个参数你可以自定义任务的拒绝策略。如果线程池中所有的线程都在忙碌,并且工作队 列也满了(前提是工作队列是有界队列),那么此时提交任务,线程池就会拒绝接收。至于拒绝的策略, 你可以通过handler这个参数来指定。
ThreadPoolExecutor已经提供了以下4种策略。
- CallerRunsPolicy:提交任务的线程自己去执行该任务。
- AbortPolicy:默认的拒绝策略,会throws RejectedExecutionException。
- DiscardPolicy:直接丢弃任务,没有任何异常抛出。
- DiscardOldestPolicy:丢弃最老的任务,其实就是把最早进入工作队列的任务丢弃,然后把新任务加入 到工作队列。
Java在1.6版本还增加了 allowCoreThreadTimeOut(boolean value) 方法,它可以让所有线程都支持超时,这 意味着如果项目很闲,就会将项目组的成员都撤走。
使用线程池要注意些什么
考虑到ThreadPoolExecutor的构造函数实在是有些复杂,所以Java并发包里提供了一个线程池的静态工厂类
Executors,利用Executors你可以快速创建线程池。不过目前大厂的编码规范中基本上都不建议使用 Executors了,所以这里我就不再花篇幅介绍了。 不建议使用Executors的最重要的原因是:Executors提供的很多方法默认使用的都是无界的 LinkedBlockingQueue,高负载情境下,无界队列很容易导致OOM,而OOM会导致所有请求都无法处理, 这是致命问题。所以强烈建议使用有界队列。
使用有界队列,当任务过多时,线程池会触发执行拒绝策略,线程池默认的拒绝策略会throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制catch它,所以开发人员 很容易忽略。因此默认拒绝策略要慎重使用。如果线程池处理的任务非常重要,建议自定义自己的拒绝策 略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
使用线程池,还要注意异常处理的问题,例如通过ThreadPoolExecutor对象的execute()方法提交任务时, 如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常 了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。虽然线程池提供了很多用于异常处 理的方法,但是最稳妥和简单的方案还是捕获所有异常并按需处理,你可以参考下面的示例代码。
try { //业务逻辑
} catch (RuntimeException x) { //按需处理
} catch (Throwable x) { //按需处理
}
23|Future:如何用多线程实现最优的“烧水泡茶”程序?
如何获取任务执行结果
Java通过ThreadPoolExecutor提供的3个submit()方法和1个FutureTask工具类来支持获得任务执行结果的需 求。下面我们先来介绍这3个submit()方法,这3个方法的方法签名如下。
// 提交Runnable任务
Future<?> submit(Runnable task);
// 提交Callable任务
<T> Future<T> submit(Callable<T> task);
// 提交Runnable任务及结果引用
<T> Future<T> submit(Runnable task, T result);
你会发现它们的返回值都是Future接口,Future接口有5个方法,我都列在下面了,它们分别是
- 取消任务的 方法
cancel() - 判断任务是否已取消的方法
isCancelled() - 判断任务是否已结束的方法
isDone() - 2个获得 任务执行结果的
get()和get(timeout, unit),其中最后一个get(timeout, unit)支持超时机制。
通过Future接口 的这5个方法你会发现,我们提交的任务不但能够获取任务执行结果,还可以取消任务。不过需要注意的 是:这两个get()方法都是阻塞式的,如果被调用的时候,任务还没有执行完,那么调用get()方法的线程会阻 塞,直到任务执行完才会被唤醒。
这3个submit()方法之间的区别在于方法参数不同,下面我们简要介绍一下。
1. 提交Runnable任务 submit(Runnable task) :这个方法的参数是一个Runnable接口,Runnable接
口的run()方法是没有返回值的,所以submit(Runnable task)这个方法返回的Future仅可以用来断
言任务已经结束了,类似于Thread.join()。
2. 提交Callable任务 submit(Callable<T> task):这个方法的参数是一个Callable接口,它只有一个call()方法,并且这个方法是有返回值的,所以这个方法返回的Future对象可以通过调用其get()方法来获取任务的执行结果。
3. 提交Runnable任务及结果引用 submit(Runnable task, T result):这个方法很有意思,假设这
个方法返回的Future对象是f,f.get()的返回值就是传给submit()方法的参数result。这个方法该怎么用 呢?下面这段示例代码展示了它的经典用法。需要你注意的是Runnable接口的实现类Task声明了一个有 参构造函数Task(Result r),创建Task对象的时候传入了result对象,这样就能在类Task的run()方法 中对result进行各种操作了。result相当于主线程和子线程之间的桥梁,通过它主子线程可以共享数据。
下面我们再来介绍FutureTask工具类。前面我们提到的Future是一个接口,而FutureTask是一个实实在在的 工具类,这个工具类有两个构造函数,它们的参数和前面介绍的submit()方法类似,所以这里我就不再赘述 了。
FutureTask(Callable<V> callable);
FutureTask(Runnable runnable, V result);
那如何使用FutureTask呢?其实很简单,FutureTask实现了Runnable和Future接口,由于实现了Runnable 接口,所以可以将FutureTask对象作为任务提交给ThreadPoolExecutor去执行,也可以直接被Thread执 行;又因为实现了Future接口,所以也能用来获得任务的执行结果。下面的示例代码是将FutureTask对象提 交给ThreadPoolExecutor去执行。
// 创建FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(()-> 1+2); // 创建线程池
ExecutorService es = Executors.newCachedThreadPool();
// 提交FutureTask
es.submit(futureTask);
// 获取计算结果
Integer result = futureTask.get();
FutureTask对象直接被Thread执行的示例代码如下所示。相信你已经发现了,利用FutureTask对象可以很容 易获取子线程的执行结果。
// 创建FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(()-> 1+2);
// 创建并启动线程
Thread T1 = new Thread(futureTask);
T1.start();
// 获取计算结果
Integer result = futureTask.get();
总结
利用Java并发包提供的Future可以很容易获得异步任务的执行结果,无论异步任务是通过线程池 ThreadPoolExecutor执行的,还是通过手工创建子线程来执行的。Future可以类比为现实世界里的提货单, 比如去蛋糕店订生日蛋糕,蛋糕店都是先给你一张提货单,你拿到提货单之后,没有必要一直在店里等着, 可以先去干点其他事,比如看场电影;等看完电影后,基本上蛋糕也做好了,然后你就可以凭提货单领蛋糕 了。
利用多线程可以快速将一些串行的任务并行化,从而提高性能;如果任务之间有依赖关系,比如当前任务依 赖前一个任务的执行结果,这种问题基本上都可以用Future来解决。在分析这种问题的过程中,建议你用有 向图描述一下任务之间的依赖关系,同时将线程的分工也做好,类似于烧水泡茶最优分工方案那幅图。对照 图来写代码,好处是更形象,且不易出错。
24|CompletableFuture:异步编程没那么难
异步化,是并行方案得以实施的基础,更深入地讲其实就是:利用多线程优化性能这个核心方案得以实施的 基础 。看到这里,相信你应该就能理解异步编程最近几年为什么会大火了,因为优化性能是互联网大厂的一 个核心需求啊。Java在1.8版本提供了CompletableFuture来支持异步编程,CompletableFuture有可能是你 见过的最复杂的工具类了,不过功能也着实让人感到震撼。
CompletableFuture的核心优势
为了领略CompletableFuture异步编程的优势,这里我们用CompletableFuture重新实现前面曾提及的烧水 泡茶程序。首先还是需要先完成分工方案,在下面的程序中,我们分了3个任务:任务1负责洗水壶、烧开 水,任务2负责洗茶壶、洗茶杯和拿茶叶,任务3负责泡茶。其中任务3要等待任务1和任务2都完成后才能开 始。这个分工如下图所示。
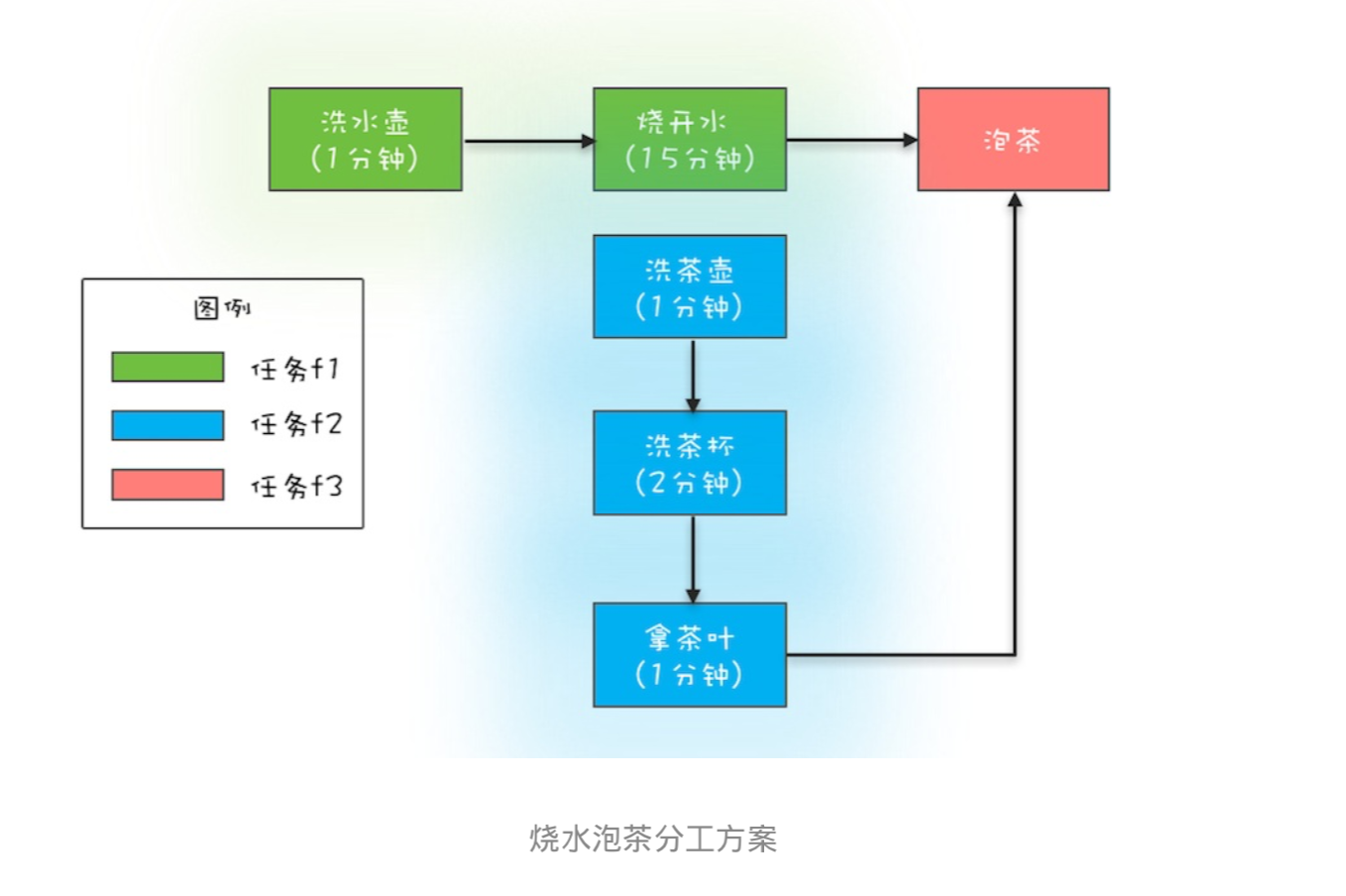
下面是代码实现,你先略过 runAsync()、supplyAsync()、thenCombine()这些不太熟悉的方法,从大局上 看,你会发现:
- 无需手工维护线程,没有繁琐的手工维护线程的工作,给任务分配线程的工作也不需要我们关注;
- 语义更清晰,例如
f3 = f1.thenCombine(f2, ()->{})能够清晰地表述“任务3要等待任务1和任务2都完成后才能开始”; 代码更简练并且专注于业务逻辑,几乎所有代码都是业务逻辑相关的。
//任务1:洗水壶->烧开水 CompletableFuture<Void> f1 = CompletableFuture.runAsync(()->{ System.out.println("T1:洗水壶..."); sleep(1, TimeUnit.SECONDS); System.out.println("T1:烧开水..."); sleep(15, TimeUnit.SECONDS); }); //任务2:洗茶壶->洗茶杯->拿茶叶 CompletableFuture<String> f2 = CompletableFuture.supplyAsync(()->{ System.out.println("T2:洗茶壶..."); sleep(1, TimeUnit.SECONDS); System.out.println("T2:洗茶杯..."); sleep(2, TimeUnit.SECONDS); System.out.println("T2:拿茶叶..."); sleep(1, TimeUnit.SECONDS); return "⻰井"; }); //任务3:任务1和任务2完成后执行:泡茶 CompletableFuture<String> f3 =f1.thenCombine(f2, (__, tf)->{ System.out.println("T1:拿到茶叶:" + tf); System.out.println("T1:泡茶..."); return "上茶:" + tf; }); //等待任务3执行结果 System.out.println(f3.join()); void sleep(int t, TimeUnit u) { try { u.sleep(t); }catch(InterruptedException e){} } // 一次执行结果: T1:洗水壶... T2:洗茶壶... T1:烧开水... T2:洗茶杯... T2:拿茶叶... T1:拿到茶叶:⻰井 T1:泡茶... 上茶:⻰井
领略CompletableFuture异步编程的优势之后,下面我们详细介绍CompletableFuture的使用,首先是如何 创建CompletableFuture对象。
创建CompletableFuture对象
创建CompletableFuture对象主要靠下面代码中展示的这4个静态方法,我们先看前两个。在烧水泡茶的例 子中,我们已经使用了runAsync(Runnable runnable)和supplyAsync(Supplier<U> supplier),它们之间的区别是:Runnable 接口的run()方法没有返回值,而Supplier接口的get()方法是有 返回值的。
//TODO
前两个方法和后两个方法的区别在于:后两个方法可以指定线程池参数。
25|CompletionService:如何批量执行异步任务
26|ForkJoin:单机版的MapReduce
前面几篇文章我们介绍了线程池、Future、CompletableFuture和CompletionService,仔细观察你会发现这些工具类都是在帮助我们站在任务的视角来解决并发问题,而不是让我们纠缠在线程之间如何协作的细节上 (比如线程之间如何实现等待、通知等)。
- 对于简单的并行任务,你可以通过“线程池+Future”的方案来 解决;
- 如果任务之间有聚合关系,无论是AND聚合还是OR聚合,都可以通过CompletableFuture来解决;
- 而批量的并行任务,则可以通过CompletionService来解决。
我们一直讲,并发编程可以分为三个层面的问题,分别是分工、协作和互斥,当你关注于任务的时候,你会发现你的视角已经从并发编程的细节中跳出来了,你应用的更多的是现实世界的思维模式,类比的往往是现实世界里的分工,所以我把线程池、Future、CompletableFuture和CompletionService都列到了分工里面。
上面提到的简单并行、聚合、批量并行这三种任务模型,基本上能够覆盖日常工作中的并发场景了,但还是 不够全面,因为还有一种“分治”的任务模型没有覆盖到。分治,顾名思义,即分而治之,是一种解决复杂 问题的思维方法和模式;具体来讲,指的是把一个复杂的问题分解成多个相似的子问题,然后再把子问题分 解成更小的子问题,直到子问题简单到可以直接求解。理论上来讲,解决每一个问题都对应着一个任务,所 以对于问题的分治,实际上就是对于任务的分治。
分治思想在很多领域都有广泛的应用,例如算法领域有分治算法(归并排序、快速排序都属于分治算法,二分法查找也是一种分治算法);大数据领域知名的计算框架MapReduce背后的思想也是分治。既然分治这 种任务模型如此普遍,那Java显然也需要支持,Java并发包里提供了一种叫做Fork/Join的并行计算框架,就 是用来支持分治这种任务模型的。
27|并发工具类热点问题答疑
- while(true) 总不让人省心
- signalAll()总让人省心
- Sempaphore需要锁中锁
- 锁的申请和释放要成对出现
- 回调总要关心执行线程是谁
- 共享线程池:有福同享就要有难同当
- 线上问题定位的利器:线程栈dump
总结
Java并发工具类到今天为止,就告一段落了,由于篇幅原因,不能每个工具类都详细介绍。Java并发工具类 内容繁杂,熟练使用是需要一个过程的,而且需要多加实践。希望你学完这个模块之后,遇到并发问题时最 起码能知道用哪些工具可以解决。至于工具使用的细节和最佳实践,我总结的也只是我认为重要的。由于每 个人的思维方式和编码习惯不同,也许我认为不重要的,恰恰是你的短板,所以这部分内容更多地还是需要 你去实践,在实践中养成良好的编码习惯,不断纠正错误的思维方式。