TOC
众所周知,Mysql中的索引结构是用B+Tree实现的,那么具体是如何来构建的呢?
B+数据结构
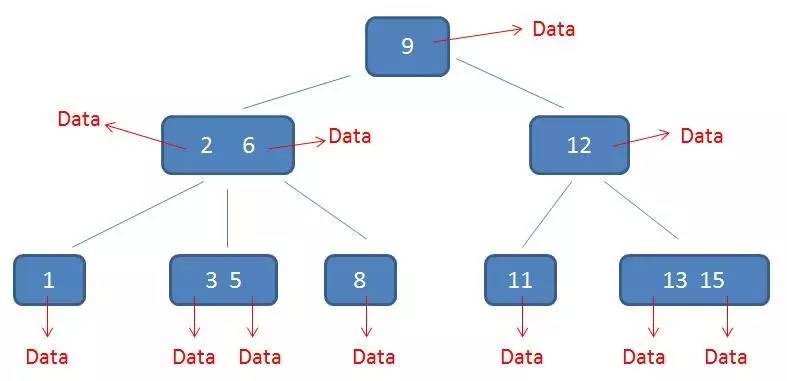
B-树中的卫星数据(Satellite Information):
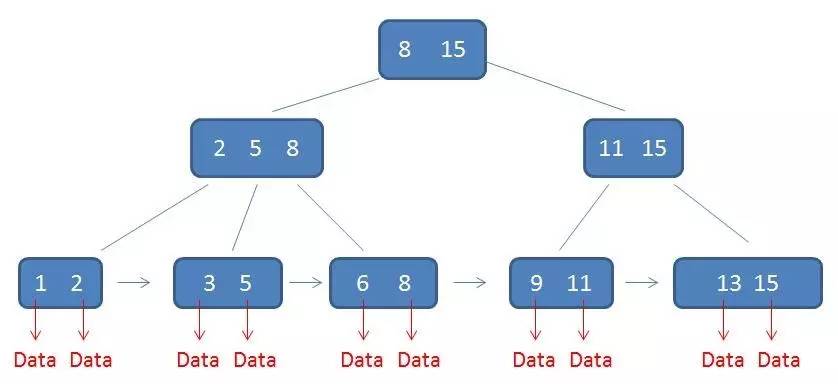
B+树中的卫星数据(Satellite Information):
B+树特点:
- 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 每一个父节点的元素都出现在子节点中,是子节点的最大(或最小)元素。
- 至于叶子节点,由于父节点的元素都出现在子节点,因此所有叶子节点包含了全量元素信息。
- 并且每一个叶子结点都带有指向下一个节点的指针,形成了有序链表。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所谓卫星数据,指的是索引元素所只想的数据记录,比如数据库中的某一行。
- 在B-树中,无论中间节点还是叶子节点都带有卫星数据。
- 而在B+树当中,只有叶子结点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联。
在数据库的聚簇索引中,叶子节点直接包含卫星数据。
在非聚簇索引中,叶子节点带有指向卫星数据的指针。
B+树的中间节点没有卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素。这就意味着,相同数据量的情况下,B+树的结构比B-树更加“矮胖”,因此查询时IO次数也更少。
其次,B+树的查询必须是最终查找到叶子结点,而B-树只要找到匹配的元素即可,无论是匹配元素处于中间节点还是叶子节点。因此查找性能并不稳定。而B+树的每一次查找都是稳定的。
范围查找更简便,只需要遍历链表即可。而B-树需要中序遍历
MYSQL 中的索引
普通索引
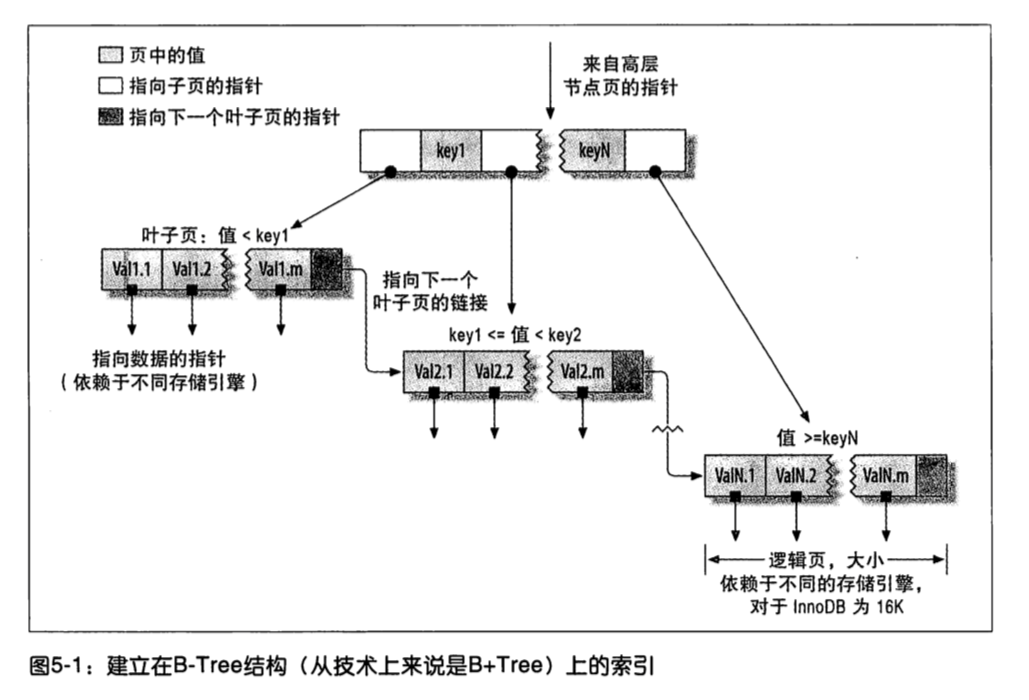
B+Tree索引能够加快访问数据的速度,因为存储引擎不再需要进行全表扫描来获取需要的数据,取而代之的是从索引的根节点开始搜索。
- 根节点的槽中存放了指向子节点的指针,存储引擎根据这些指针向下层查找。
- 通过比较节点页的值和要查找的值可以找到合适的指针进入下层节点,这些指针实际上定义了子节点页中值的上限和下限。
- 最终存储引擎要么是找到对应的值,要么该记录不存在。
- 叶子节点比较特殊,他们的指针指向的是被索引的数据,而不是其他的节点页(不同引擎的“指针”类型不同)。
图5-1描绘了一个节点和其对应的叶子结点,其实在根节点和叶子节点之间可能有很多层节点页。树的深度和表的大小直接相关。B+Tree对索引列是顺序组织存储的,所以很适合查找范围数据。
联合索引
假设有如下数据表:
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m','f'),
key(last_name,first_name,dob)
)
图5-2显示了该索引是如何组织数据的存储的。
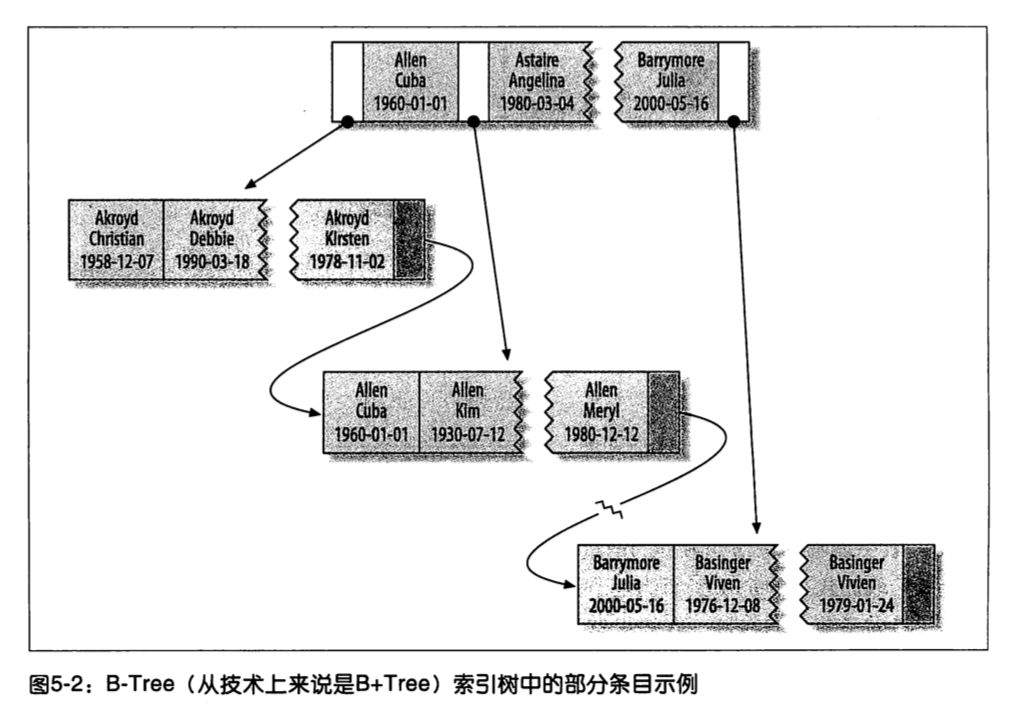
有图5-2可看出,联合索引,每层节点三个字段都在,并非网上说的只有前面的字段。同时索引对多个值进行排序的依据是建表语句中定义索引时列的顺序。看一下最后两个条目,两个人的姓和名都一样,则根据他们的出生日期来排列顺序。
了解了索引的结构,我们也就能理解最左前缀原则的原理存在的原因。
B+Tree索引的限制:
- 最左前缀原则
- 不能跳过中间的某个字段
- 如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引优化查找。(如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。)