TOC
Matt Klein的一篇精彩的博客“服务网格中的数据平面与控制平面”
原文链接:https://blog.envoyproxy.io/service-mesh-data-plane-vs-control-plane-2774e720f7fc
As the idea of the “service mesh” has become increasingly popular over the last two years and as the number of entrants into the space has swelled, I have seen a commensurate increase in confusion among the overall tech community around how to compare and contrast the different players.
The situation can best be summarized by the following series of tweets that I wrote in July:
The previous tweets mention several different projects (Linkerd, NGINX, HAProxy, Envoy, and Istio) but more importantly introduce the general concepts of the service mesh data plane and the control plane. In this post I will step back and discuss what I mean by the terms data plane and control plane at a very high level and then discuss how the terms relate to the projects mentioned in the tweets.
What is a service mesh, really?
Figure 1: Service mesh overview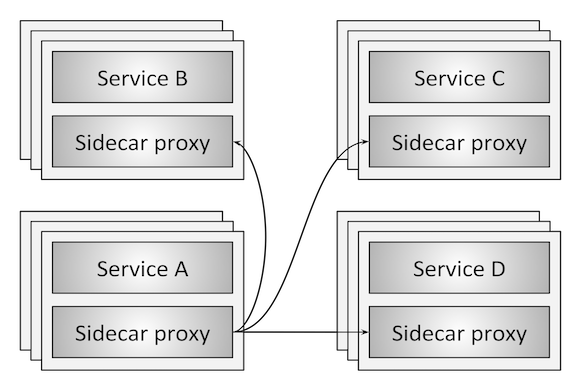
Figure 1 illustrates the service mesh concept at its most basic level. There are four service clusters (A-D). Each service instance is colocated with a sidecar network proxy. All network traffic (HTTP, REST, gRPC, Redis, etc.) from an individual service instance flows via its local sidecar proxy to the appropriate destination. Thus, the service instance is not aware of the network at large and only knows about its local proxy. In effect, the distributed system network has been abstracted away from the service programmer.
The data plane
In a service mesh, the sidecar proxy performs the following tasks:
- Service discovery: What are all of the upstream/backend service instances that are available?
- Health checking: Are the upstream service instances returned by service discovery healthy and ready to accept network traffic? This may include both active (e.g., out-of-band pings to a
/healthcheckendpoint) and passive (e.g., using 3 consecutive 5xx as an indication of an unhealthy state) health checking. - Routing: Given a REST request for
/foofrom the local service instance, to which upstream service cluster should the request be sent? - Load balancing: Once an upstream service cluster has been selected during routing, to which upstream service instance should the request be sent? With what timeout? With what circuit breaking settings? If the request fails should it be retried?
- Authentication and authorization: For incoming requests, can the caller be cryptographically attested using mTLS or some other mechanism? If attested, is the caller allowed to invoke the requested endpoint or should an unauthenticated response be returned? 主要是端到端的mTLS加密、服务间认证授权、终端用户认证授权
- Observability: For each request, detailed statistics, logging, and distributed tracing data should be generated so that operators can understand distributed traffic flow and debug problems as they occur.一般我们说的可观测性(Observability),包含Logging、Tracing、Metrics 这三部分
All of the previous items are the responsibility of the service mesh data plane. In effect, the sidecar proxy is the data plane. Said another way, the data plane is responsible for conditionally translating, forwarding, and observing every network packet that flows to and from a service instance.
The control plane
The network abstraction that the sidecar proxy data plane provides is magical. However, how does the proxy actually know to route /foo to service B? How is the service discovery data that the proxy queries populated? How are the load balancing, timeout, circuit breaking, etc. settings specified? How are deploys accomplished using blue/green or gradual traffic shifting semantics? Who configures systemwide authentication and authorization settings?
All of the above items are the responsibility of the service mesh control plane. The control plane takes a set of isolated stateless sidecar proxies and turns them into a distributed system.
The reason that I think many technologists find the split concepts of data plane and control plane confusing is that for most people the data plane is familiar while the control plane is foreign. We’ve been around physical network routers and switches for a long time. We understand that packets/requests need to go from point A to point B and that we can use hardware and software to make that happen. The new breed of software proxies are just really fancy versions of tools we have been using for a long time.
Figure 2: Human control plane 
However, we have also been using control planes for a long time, though most network operators might not associate that portion of the system with a piece of technology. There reason for this is simple — most control planes in use today are… us.
Figure 2 shows what I call the “human control plane.” In this type of deployment (which is still extremely common), a (likely grumpy) human operator crafts static configurations — potentially with the aid of some scripting tools — and deploys them using some type of bespoke process to all of the proxies. The proxies then consume the configuration and proceed with data plane processing using the updated settings.
Figure 3: Advanced service mesh control plane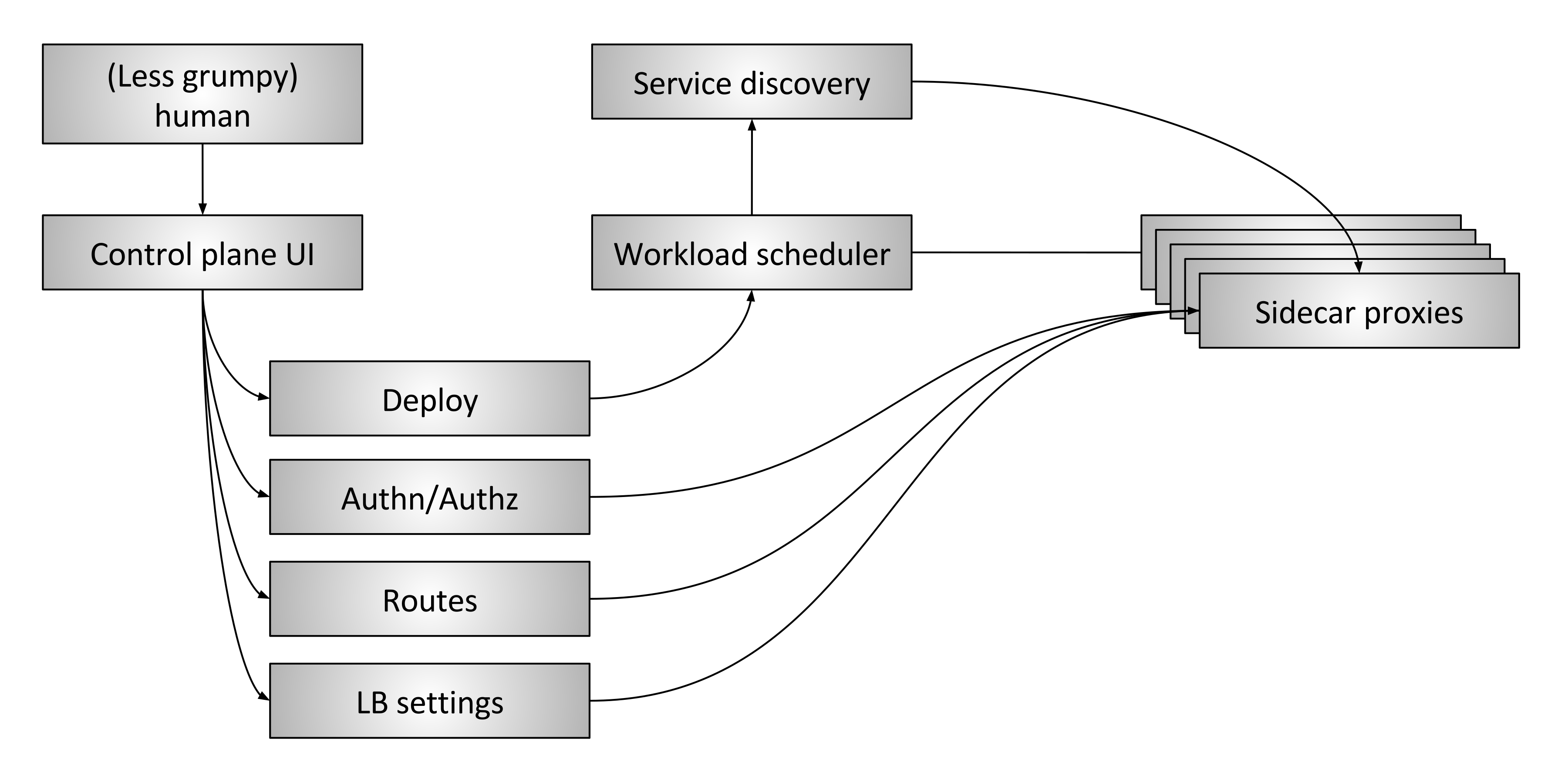
Figure 3 shows an “advanced” service mesh control plane. It is composed of the following pieces:
- The human: There is still a (hopefully less grumpy) human in the loop making high level decisions about the overall system.
- Control plane UI: The human interacts with some type of UI to control the system. This might be a web portal, a CLI, or some other interface. Through the UI, the operator has access to global system configuration settings such as deploy control (blue/green and/or traffic shifting), authentication and authorization settings, route table specification (e.g., when service A requests
/foowhat happens), and load balancer settings (e.g., timeouts, retries, circuit breakers, etc.). - Workload scheduler: Services are run on an infrastructure via some type of scheduling system (e.g., Kubernetes or Nomad). The scheduler is responsible for bootstrapping a service along with its sidecar proxy.
- Service discovery: As the scheduler starts and stops service instances it reports liveness state into a service discovery system.
- Sidecar proxy configuration APIs: The sidecar proxies dynamically fetch state from various system components in an eventually consistent way without operator involvement. The entire system composed of all currently running service instances and sidecar proxies eventually converge. Envoy’s universal data plane API is one such example of how this works in practice.
Ultimately, the goal of a control plane is to set policy that will eventually be enacted by the data plane. More advanced control planes will abstract more of the system from the operator and require less handholding (assuming they are working correctly!).
Data plane vs. control plane summary
Service mesh data plane: Touches every packet/request in the system. Responsible for service discovery, health checking, routing, load balancing, authentication/authorization, and observability.
Service mesh control plane: Provides policy and configuration for all of the running data planes in the mesh. Does not touch any packets/requests in the system. The control plane turns all of the data planes into a distributed system.
Current project landscape
With the above explanation out of the way, let’s take a look at the current service mesh landscape.
Instead of doing an in-depth analysis of each solution above, I’m going to briefly touch on some of the points that I think are causing the majority of the ecosystem confusion right now.
Linkerd was one of the first service mesh data plane proxies on the scene in early 2016 and has done a fantastic job of increasing awareness and excitement around the service mesh design pattern. Envoy followed about 6 months later (though was in production at Lyft since late 2015). Linkerd and Envoy are the two projects that are most commonly mentioned when discussing “service meshes.”
Istio was announced May, 2017. The project goals of Istio look very much like the advanced control plane illustrated in figure 3. The default proxy of Istio is Envoy. Thus, Istio is the control plane and Envoy is the data plane. In a short time, Istio has garnered a lot of excitement, and other data planes have begun integrations as a replacement for Envoy (both Linkerd and NGINX have demonstrated Istio integration). The fact that it’s possible for a single control plane to use different data planes means that the control plane and data plane are not necessarily tightly coupled. An API such as Envoy’s universal data plane API can form a bridge between the two pieces of the system.
Nelson and SmartStack help further illustrate the control plane vs. data plane divide. Nelson uses Envoy as its proxy and builds a robust service mesh control plane around the HashiCorp stack (i.e. Nomad, etc.). SmartStack was perhaps the first of the new wave of service meshes. SmartStack forms a control plane around HAProxy or NGINX, further demonstrating that it’s possible to decouple the service mesh control plane and the data plane.
The service mesh microservice networking space is getting a lot of attention right now (rightly so!) with more projects and vendors entering all the time. Over the next several years, we will see a lot of innovation in both data planes and control planes, and further intermixing of the various components. The ultimate result should be microservice networking that is more transparent and magical to the (hopefully less and less grumpy) operator.
Key takeaways
- A service mesh is composed of two disparate pieces: the data plane and the control plane. Both are required. Without both the system will not work.
- Everyone is familiar with the control plane — albeit the control plane might be you!
- All of the data planes compete with each other on features, performance, configurability, and extensibility.
- All of the control planes compete with each other on features, configurability, extensibility, and usability.
- A single control plane may contain the right abstractions and APIs such that multiple data planes can be used.
服务网格控制平面“为网格中所有正在运行的数据平面提供策略和配置”,并且“控制平面将所有数据平面转变为分布式系统。”最终,控制平面的目标是设置将由数据平面制定的策略。控制平面可以通过配置文件,API调用和用户界面来实现。选择的实现方法通常取决于用户的角色,以及他们的目标和技术能力。
例如,产品所有者可能想要在应用程序中发布新功能,这里UI通常是最合适的控制平面,因为这可以显示系统的可理解视图并且还提供一些导轨。但是,对于想要配置一系列低级防火墙规则的网络运维人员,使用CLI或配置文件将提供更细粒度(高级用户风格)控制,并且还便于自动化。